
System redundancy is a must have for all kind of control room application services, especially if they are mission critical like voice communications. This page will showcase redundancy concepts used and implemented, starting from multiple session support over multi device support down to network link and core system redundancy.
We will show application level state synchronization between multiple client devices, as well as state synchronization of multiple core nodes. Once core node redundancy is introduced we show inner core redundancy for media distribution. The redundancy description finished with a network redundancy introduction.
Our redundancy concept will work solely on state synchronization and Multicast based routing. It is a dead simple concept, tailored to the use case Mission Control Room Conferencing. It eliminates costly redundant devices, services or hardware and instead allows to use Commercial of the Shelf (COTS) hardware for a VoCS system. Redundancy within the system is done by design and architecture. In contrast to a lot of other solutions our core redundancy concept is implemented within the clients of the system.
Openvocs is using a multi layered redundancy concept. In contrast to common redundancy concepts, most of the redundant functionality is implemented within the client, as close to the user as it gets. This is done to ensure the human operating the system is able to act as last kind of resort for redundancy decisions. Different kinds of errors may occur during operation of VoCS. An informed user is able to decide for recovery actions, when automatic recovery fails. More of error handling will be outlined later within the chapter failure cases.
The first level of redundancy is session redundancy. Sessions span over different clients, based on the user login and role selection. Within the session all state changes are synchronized based on user broadcast messages. A switch from one client to another will allows seamless operation of VoCS services.
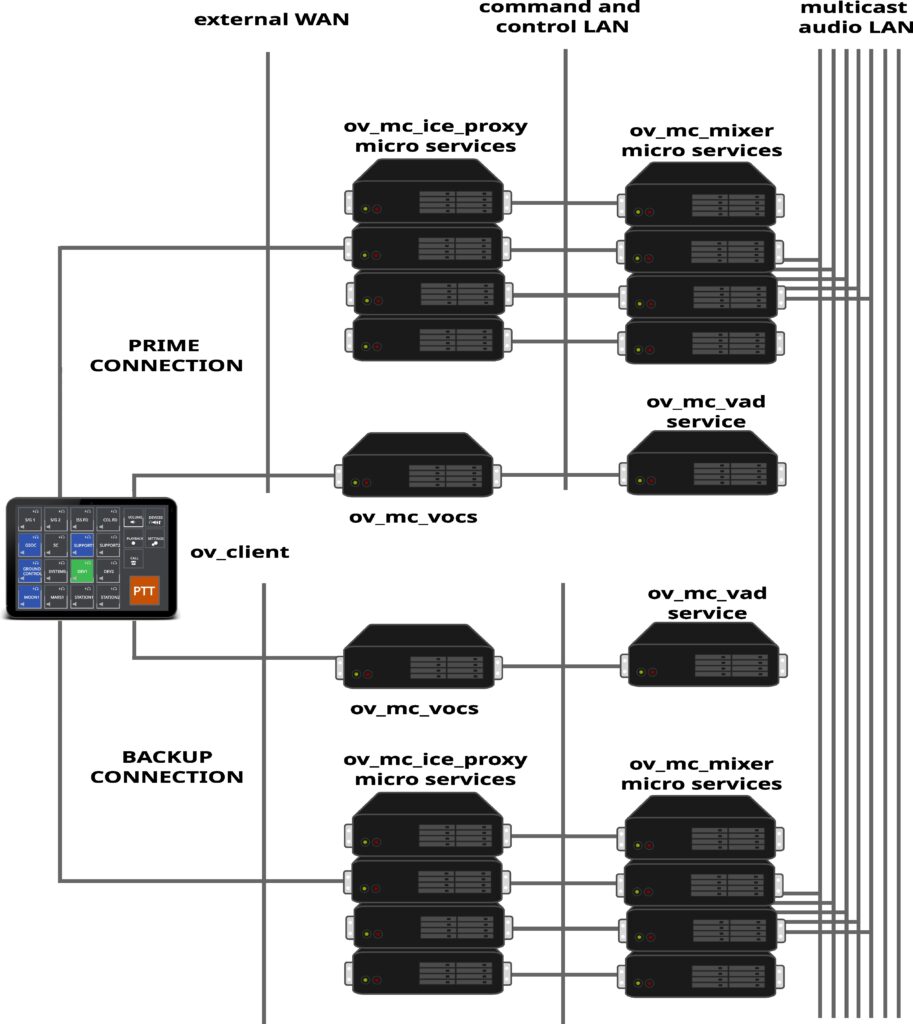
Second level of redundancy is backend redundancy. A client may connect to more than one backend at a time and synchronizes the states within different backends. This way a switch from one backend to the other will allow seamless operation of the VoCS services.
Third level of redundancy is inner core redundancy based on the Voiceloops, which are transmitted over multicast messaging. Once the audio path leaves the media proxy a multicast IP is used for media transmission and multiple mixer services from different backends may listen to the same multicast IP to generate the mixed stream.
Session Redundancy
Session redundancy is a special redundancy concept for openvocs. A session originates with user login. Once the user is authenticated and authorized the client of the user becomes part of a session. Each client is identified over a unique id. Within a session each action e.g. state changes will be synchronized. Each client will also have a dedicated state machine for Voiceloop states as each client login will be connected with a dedicated mixing service. Each client need to interact with it’s own mixing service to set the states the user has selected. Therefore each client to switches states independently.
For synchronization a user broadcast is used. This broadcast will forward any state change information to any client connected. Each client will check if it is the originator of the broadcast based on the client id. If it is the originator no additional action needs to be performed. If the client is not the originator of the broadcast it will check its own state in correlation to the state of the broadcast message. If the state is different it will send a corresponding switch command to the backend. This way state switches are distributed to all clients within a session.
Each client switches the states independently from each other soley based on the user broadcast send.
Example of session redundancy:
Client A,B and C are in a session based on the same login information (same user, same role). The user switches on Voiceloop 1 at client A. Once the switch command arrives a the frontends signaling server a broadcast message is generated and distributed to all clients within the session.
Client B and C will recognize they are not the originator of the broadcast based on the client ID included within the broadcast message. They check the state of the Voiceloop 1 and will identify the Voiceloop is not switched on. As the broadcast contains a switch on command both clients will generate a Switch on message and send the message to the signaling server. The signaling server forwards the request to the clients mixing service and generate a new broadcast with the state Voiceloop 1 on. This broadcast is again distributed to all clients A,B,C, which will check if it’s own state for Voiceloop 1 is set to on. Once all clients have switched the Voiceloop 1 to on, no more messages are generated and all will have the same state.
Session redundancy is persisted within the backend. After logging out of all clients the session is still present within the frontends database. Once the user logs in again the states of the session will be distributed to the client, this time without any client id, so the client checks if it has the same states and if not send the switch commands for all Voiceloops.
This type of session redundancy is a new concept for Voice Communication Systems. States are syncronized between all clients based on the broadcasts messages. Switching from one client to another will allow seemless operations, as the participation states for Voiceloops are always the same within the session.
Backend Redundancy
Backend redundancy is quite simple. A client connects to more than one backend at a time and will send all switch commands to all connected backends. This way the mixing services are synchronized within different backends.
The client simply syncronizes it’s own states within the different backends. Currently two backends are supportet in parallel. This forms a full backend recovery system.
To prevent echos and feedbacks the client has only one backend active at a time. Active means the audio path of the microphone is connected to one and only one backend at any time.
A user may switch the audio path to a different backend within the control menu of the client. Due to inner core redundancy the output of all Voiceloops is synchronized within different backend connections. So there is no difference in the audio received, but a difference in the path the audio is transmitted to the system and a difference in of the whole backend used.
This way backend errors or issues may be recovered by a backend switch on user command.
Inner Core Redundancy
To introduce inner core redundancy we start with the audio path of a connection. Each audio connection from a client is terminated at the media proxy. From client to proxy the audio path is a secured singlecast connection. The proxy forwards the audio to the Multicast IP of the Voiceloop.
Voiceloop selection is done by signaling over the signaling proxy. Whenever a Voiceloop is selected for talk, the signaling proxy communicates with the media proxy to switch the Multicast IP on for transmission. Once the transmission is switched on, the proxy will forward any audio received to the respective Multicast IP.
The mixing services of any users will receive the audio via Multicast transmission and mix the stream for reception of clients. Reception is done with forwarding a stream from the mixer service back to the media proxy on a dedicated pre coordinated port. Every audio received at that port is forwarded by be media proxy to the client.
Due to the use of Multicast between the media proxy and the mixer services different backends with different mixer services will receive the same stream as long as they are listening on the same Multicast IPs.
This is inner core redundancy. Different backends receive the same audio at the same time based on usage of multicast network connections for Voiceloop distribution.
This redundancy concept allows multiple backends to be in operations in parallel.
Network Redundancy
Network redundancy is implemented, according to the GSOC network management rules, with dual link networks. Each component must be connected over two network interfaces with interface bounding activated. This way maintenance of the network will have no impact to operations of the service running on top of the links. In our case the VoCS services.
Having a redundant network link makes network path failures highly unlikely.
Network connections of a console should be cabled with different switches for each link of the client hardware. This way a switch error will have no impact to operations. Within the backend each connection is done with dual link dual switch connections too.
The whole network layer is duplicated at layer 2.